Information Systems, Tribalism, and Subject Maps
Extreme Markup Languages 2006
Patrick
Durusau
(Contact information last updated May 8, 2009)
Consultant
Patrick Durusau has spent the last 15 years involved in a
variety of markup projects. Today, most of his energies are focused
on topic maps and related technologies both in ISO and OASIS. He
served on the TEI Board of Directors and is the technical lead for the
OSIS project (a standard for encoding bibles in XML). He is currently
the chair of INCITS V1, the US National Body representative to ISO/IEC
JTC1 SC34, which is the committee responsible for SGML, HyTime, DSDL
and Topic Maps. He is the ISO Project Editor for ODF (ISO 26300), a
member of the ODF TC and Chair of the ODF Metadata SC at OASIS. He
also serves as the chair of the Published Subjects TC at OASIS.
Formerly Patrick Durusau was Director of Research and
Development for the Society of Biblical Literature and was the
director of the Society of Biblical Literature Font Foundation. He
remains interested in the use of markup to enable both display and
analysis of Ancient Near Eastern texts and languages.
He was a solo law practioner in Louisiana for ten years,
accepting cases that ran from seption and divorce to death penalty
litigation.
Steve
Newcomb
(Contact information last updated May 8, 2009)
Coolheads Consulting
382 Walker Drive
Canandaigua, NY 14424 USA
Steve Newcomb is an information architecture methodology
pioneer, consultant, entrepreneur, and (former) university professor.
He drafted and edited the ISO/IEC 13250:2000 and :2003 Topic Maps
International Standard, also known as "XTM" ("XML Topic Maps"), and he
drafted and co-edits (with the co-author of this paper) the Topic Maps
-- Reference Model. He served as editor of the ISO
Hypermedia/Time-based Structuring Language ("HyTime", ISO/IEC
10744:1992 and :1997), and of the ISO Standard Music Description
Language (ISO/IEC 10743:1996). He founded and co-chairs the "Extreme
Markup Languages" summer technical conference series of IDEAlliance,
now in its 13th year. (Update: He is now on the Program Committee of
Balisage, The Markup Conference (www.balisage.org) that at least in some minds is the successor
to the Extreme Markup Languages Conference.)
Abstract. The Topic Maps Reference Model (TMRM) provides an
analytical framework for evaluating how the integration of the
information held in diverse systems, and expressed in diverse terms,
can be achieved. It asks and assists in answering the question: "What
more do I need to integrate the information in system X with the
information in system Y?", without implying any particular methodology
or implementation strategy. The answers are helpful in evaluating the
costs and benefits of integrating of information as well as in
clarifying the various options for implementation.
Introduction
The term tribe is most
often used with reference to an indigenous society. One of the
characteristics of a tribe is the sharing of a common culture and
often a dialect. But the same term can be used to describe
information systems and their users; cultures and dialects develop
around information systems.
One way to allow communication between tribes is to
translate from the dialect of one tribe to that of another.
If translation is the only option, the question of which
tribe's dialect will be used as the target of translation becomes
very important to every tribe. Not surprisingly, every tribe
thinks its dialect is the most appropriate target for any
translation; after all, information is a key component of power.
The phenomenon of preferring one's own tribe's dialect is often
called tribalism, particularly
by the tribes whose dialects were not chosen as the target of a
translation.
The Topic Maps Reference Model (TMRM) posits that the
dialect of any tribe can be used to identify subjects, without
excluding any other tribe's dialect from participating in the same
way in a given subject map. That is to say that the TMRM neither
requires nor excludes any particular way of identifying
subjects. One consequence of this is that all systems of identification used in
information resources can be used to identify subjects in subject
maps.
Subject Maps Basics
Before demonstrating the use of an existing system for
identification of subjects it will be helpful to review the basic
principles of subject maps.
A subject map is a set of subject proxies. A subject proxy
(proxy) is a set of properties. Each property is a key/value
pair. An expression of a
subject proxy represents a subject. A subject proxy expression is
addressable; it has identity. (See Figure
1.)
Figure 1.
A subject map is a set of subject proxies, each of which
represents a single subject. Subject proxies have
expressions. A subject proxy expression consists of
properties (key/value pairs), and it has identity.
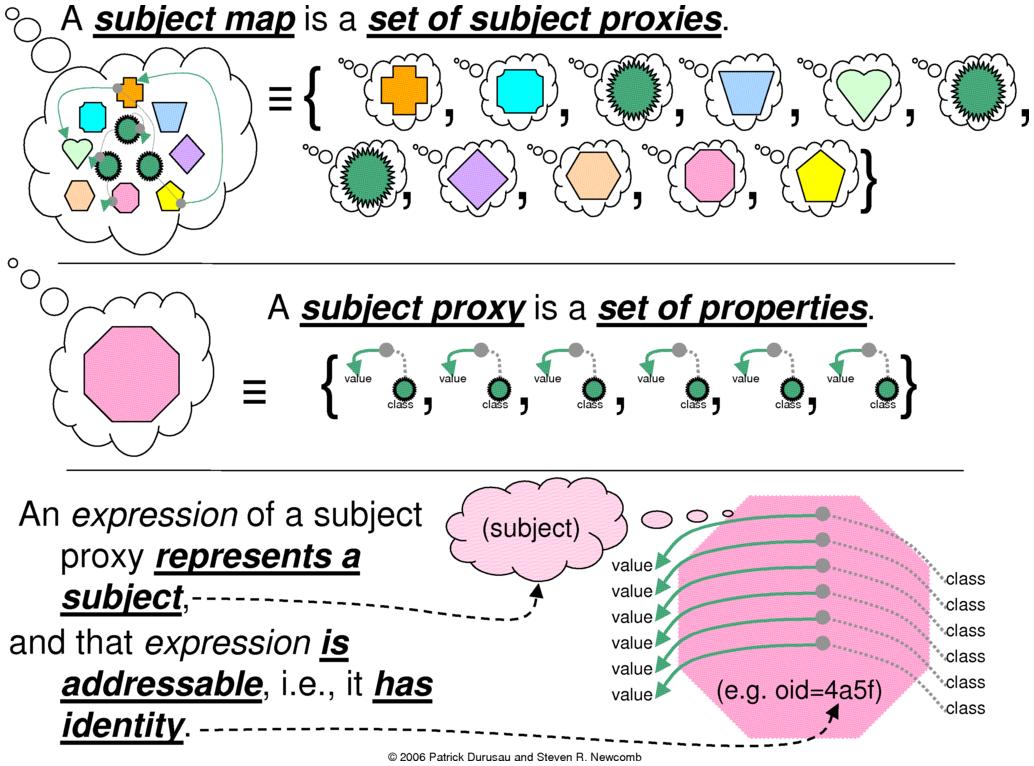
The subjects represented by subject proxies are distinct
from the proxies that represent them. The seption between
expressions (in this case, subject proxies) and the things that
they express (subjects) has sometimes been described as a
chasm or an abyss. These metaphors smack of a
Platonistic view that holds that subjects exist in some hyper-real
plane, but they can only be discussed in terms of their
representatives. However, subject maps do not require their
authors or users to adopt any such philosophical position, or, for
that matter, any other philosophical position. The primary
benefits of subject maps depend on the ability to merge different
representatives -- different subject proxies, possibly expressed
differently -- for the same subject, until each subject has only
one representative, and that one proxy reflects everything known
about the subject. That merging capability does not depend on any
one philosophical position, and it can be used in the context and
service of any such position.
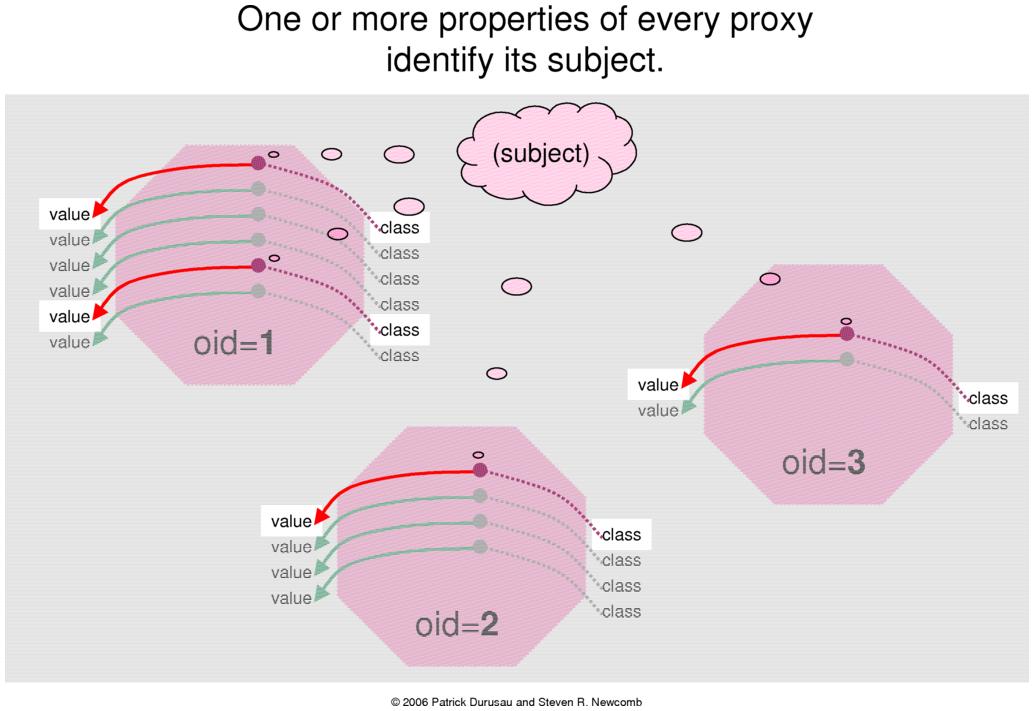
Different tribes may have expressions of completely
different subject proxies that represent the same subject. That is
to say that two different proxies can exhibit different kinds of
properties, with different kinds of values, and still be
considered to represent exactly the same subject. The insight
that they both represent the same subject might come from someone
who, for example, happens to be a member of both tribes, or who
has some other basis for arriving at such a conclusion. Perhaps
such a person has codified rules for recognizing when the two
tribes are representing the same subjects, and a computer has made
the discovery by applying those rules. (See Figures 2 and 3.)
Figure 2.
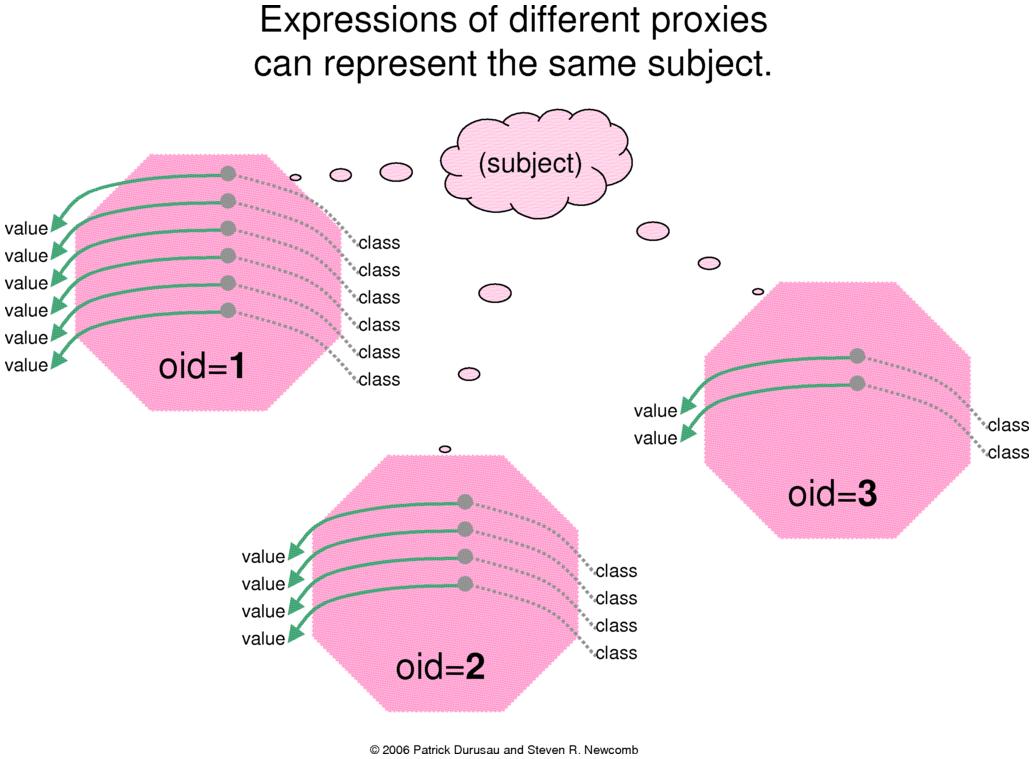
Figure 3.
With one exception, there is no requirement that any
particular subject be represented by a proxy in a given subject
map. The exception is property classes: the keys in key/value
pairs. For each class of property that appears in a given subject
map, there must be at least one proxy. (See Figure 4.)
Figure 4.
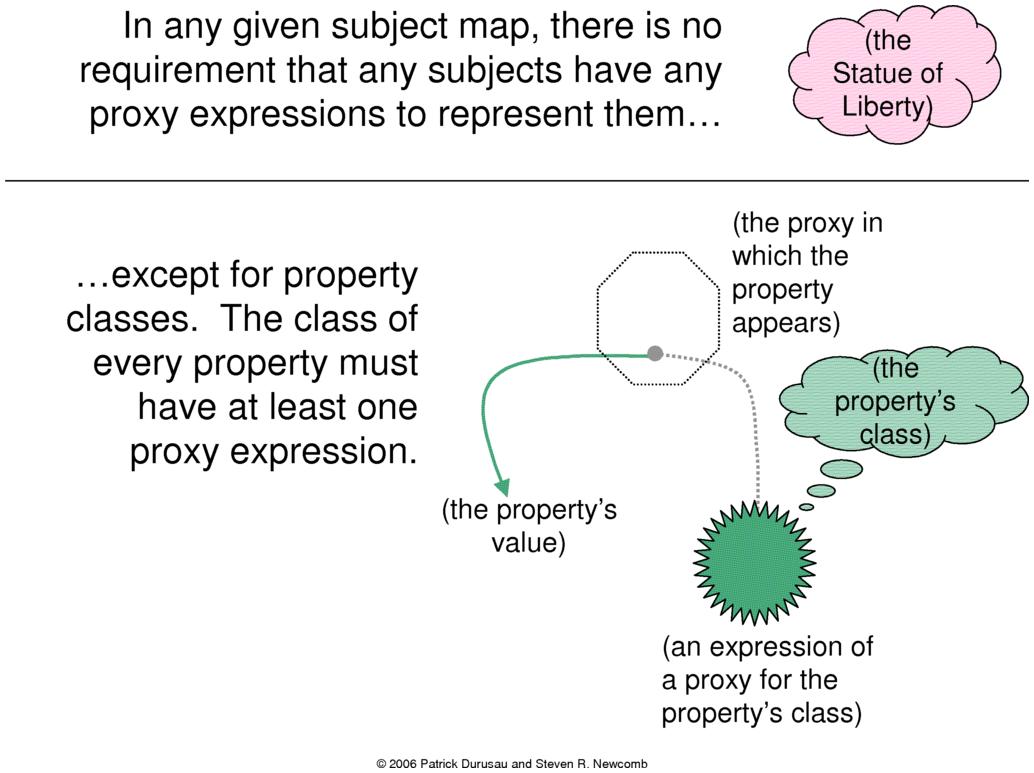
Expressions of Subject Maps
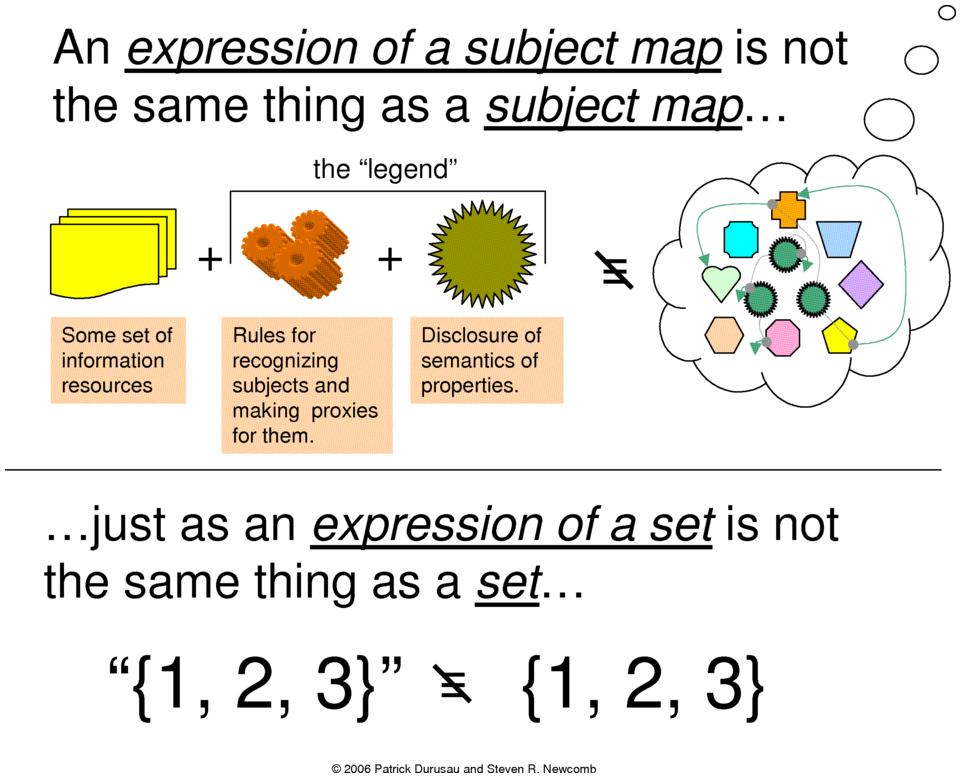
The expression of a subject map is not the same thing as a
subject map. By way of analogy, a set is not the same thing as the
expression of a set. For example, consider a set that consists of
the integers 1, 2 and 3. That particular set could be expressed
in several ways, including the following strings:
However, no expression is, in fact, the set that consists of the
integers 1, 2, and 3. There is only one such set. It exists
everywhere, and, at the same time, it exists nowhere in
particular. Nobody can touch, see, taste, feel, or smell it, nor
does it signify anything. A Platonist might claim that it simply
is, or even that it enjoys a higher level of existence. (See
Figure
5.)
Figure 5.
The importance of distinguishing between expressions of
things, on the one hand, and the things that they express, on the
other hand, can perhaps be most compellingly demonstrated for the
Extreme Markup community by considering a subject that is a
content model for an XML element type called "foo". (See Figure
6.)
Figure 6.

Clearly, the three expressions:
<!ELEMENT foo ( bar | baz)* >
<xs:complexType name="foo">
<xs:choice minOccurs="0">
maxOccurs="unbounded">
<xs:element name="bar"/>
<xs:element name="baz"/>
</xs:choice>
</xs:complexType>
<element name="foo">
<oneOrMore><choice>
<element name="bar"><text/>
</element>
<element name="baz"><text/>
</element>
</choice></oneOrMore>
</element>
...represent exactly the same subject, even though they do
so in different ways. The thing that they all have in common --
the content model that they all represent -- must be different
from all three of them. For one thing, the three expressions are
already different from each other, so they cannot possibly all
three be the same thing. Even more to the point, though, they are
expressions, and the thing that they all represent is not an
expression. It simply is, and what it is is a set of constraints
on things that claim to be "foo" elements.
When we distinguish subject maps from expressions of subject
maps, and subject proxies from expressions of subject proxies, it
becomes easier to see that different representatives for the same
subjects can be merged, even if they are expressed differently,
and even if they consist of instances of different property
classes. It also becomes apparent that, although it is a fact of
life that specific tribes may require information about subjects
to be expressed via different specific syntaxes, and/or by means
of particular kinds of properties, such diversity is not
necessarily an impediment to the colocation of information about
any given subject, even if it has been imported across tribal
boundaries.
Ultimately, no particular representational approach is
canonical. It makes sense to focus more on the subjects that are
being represented than on any particular way of identifying them
or representing information about them.
So What Dialect Does Your Tribe Speak?
When we distinguish between subjects, representatives of
subjects, and the expressions of such representatives, we find we
can use a wide variety of syntaxes, vocabularies of property
classes, etc., for expressing subject representatives, and we can
do so without seriously jeopardizing the practicality of merging
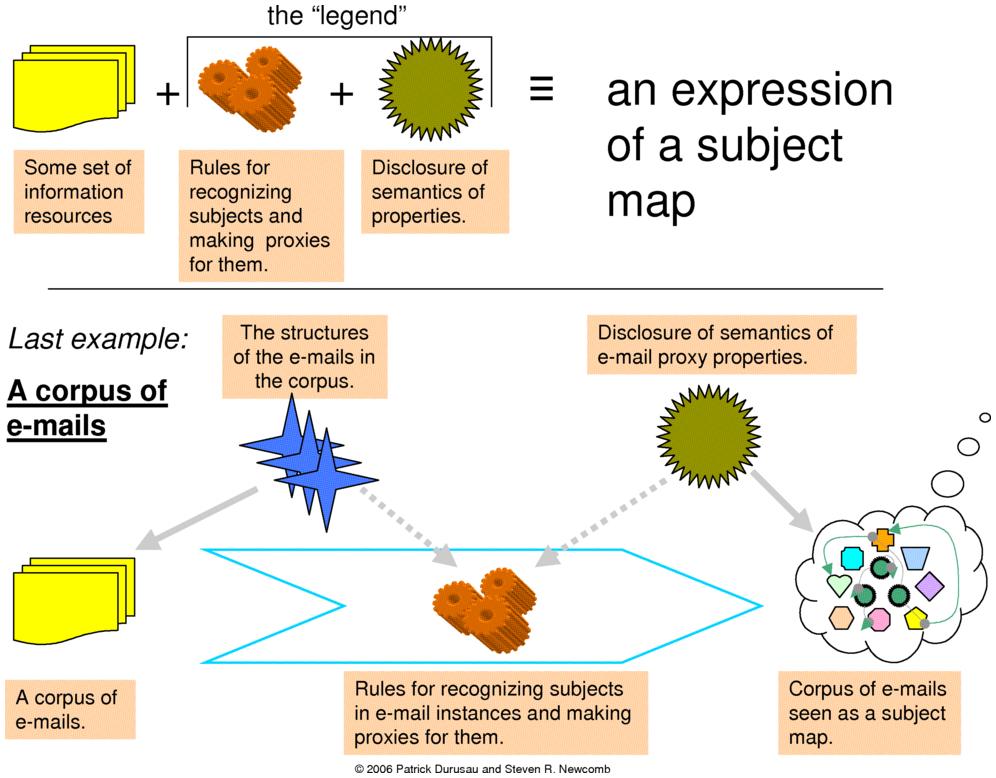
information about their subjects. For example, the email subject
map discussed in the remainder of this paper (see Figure 7.) could be expressed as an
XTM instance, a TMDM instance, as a Versavant instance, or as an
RDF instance.
Figure 7.
Each such syntax offers advantages and disadvantages, but,
in combination with rules for recognizing the subjects that they
represent, they can all support subject-centric processing,
i.e. the merging of subject proxies that have the same
subject.
The key to successful subject-centric information processing
is to recognize, honor, and exploit the ways of thinking about
subjects that are already in use by the relevant tribes, and to
maintain the integrity of each tribe's information, even as it is
merged with information coming from other tribes.
nFor example, email messages already have their own
identification scheme, as well as schemes for identifying senders,
threads, subject lines and other subjects relevant to email
messages. In other words, RFC 2822 for emails (the Email Tribe's
bible) already defines a syntax in which the subjects relevant to
email messages can be identified. Part of the global semantic
integration problem is encountering, understanding, and conserving
the value of information expressed in terms of diverse dialects that identify subjects.
The TMRM facilitates the conservation of RFC 2822 information by
allowing it to remain what it is, and to remain in its own
semantic context. At the same time, the TMRM facilitates the
exploitation of other kinds of information, expressed in different
terms and subject to different disciplines, on an equal footing
with RFC 2822 information.
The preservation of the dialect of RFC 2822 is merely
illustrative of how extant data sources that do not support
merging of representatives on their own can be incorporated into a
subject map. Tribes can continue to exploit their own dialects in
the subject maps to which they have contributed information, but
they also have opportunities to exploit information expressed in
the terms and contexts used by other tribes.
Designing a subject map
The Topic Maps Reference Model (TMRM) provides an analytical
framework for evaluating how the integration of the information
held in diverse systems, and expressed in diverse terms, can be
achieved. What follows is an illustration of subject map design.
The key questions to be answered are,
"What kinds of subjects should appear in the subject
map?"
"How can one determine whether two proxies represent
the same subject?"
"What information, other than subject identification
information, needs to be reflected in the subject proxies for
each kind of subject?"
What kinds of subjects?
Decisions as to whether any given kind of subject will be
represented in any given subject map are necessarily driven by
the requirements that the subject map is supposed to meet.
Basically, all such decisions are a matter of determining, for
each kind of subject, whether the instances of that kind of
subject should have their own perspectives on the rest of the
subject map -- i.e., whether they should have proxies.
In the case of our example -- a subject map that provides
access to an existing corpus of emails*
-- there are several obvious kinds of subjects, each instance of
which is readily identified in the corpus: email authors, email
subjects, email threads, and dates. Do we expect users to want
to access the corpus on all of these different bases? I.e.,
will a user want to access the corpus from the perspective of
any given author, or a given subject, or a given thread, or a
given date? For purposes of this discussion, we will assume the
answer to the foregoing questions is "Yes".
What are the properties of the various kinds of
subjects?
Now that we have a list of subject types, we must decide
what the properties of the proxies for the instances of each
subject type will be. For each kind of subject, we need to
invent and name the properties that will be exhibited by the
proxies of its instances. At least one of the properties that
will appear in the proxies for each kind of subject must
identify that
subject.
-
Email authors.
These subjects are the human beings who
wrote one or more of the emails in the corpus.
-
Emails. These
subjects are the emails that appear in the corpus.
-
Email subjects.
It would be more accurate to say that their
subjects are the "Subject:" lines that appear in the
emails. Theoretically, nothing prevents us from using any
means of extracting and identifying the subjects discussed
in the emails, but for purposes of this example, it makes
sense to assume that the subject lines themselves are
useful subjects to proxify.
-
Email dates.
How to populate the subject map with proxies?
Now we confront the task of actually building the subject
map from the corpus of emails. While the number of approaches
to this task is boundless, some are easier than others.
If we wish to minimize programmer effort, as opposed to
the machine cycles required to accomplish the task, we can
simply parse the corpus in such a way as to recognize each
email, and the information found in each email's header
information. Whenever an email has been recognized, its header
can be used to construct all the proxies that are relevant to
it, leaving all merging operations for later, when automated
merging will concentrate all the information about each subject
in that subject's one and only proxy.
So, for example, when we have encountered an email in the
corpus, we can simply output all the proxies that are relevant,
knowing that all of the proxies that represent the same subject
will be merged automatically, later. We output a proxy for the
person who wrote the email, endowing its proxy with any
properties that we are able to produce, given the information
provided in the email. Similarly, we output a proxy for the
email itself, a proxy for its subject line, and a proxy for its
date. The code that we used to parse the corpus of emails and
to create the proxies is found in
www.versavant.org/EML2006/ (initemail.py).
The code that was executed in order to produce a proxy is found
on lines 537-629; these lines are reproduced below:
personProxy = vsv.newProxyObject() ## create a proxy for the author
vsv.newPropertyInstance( ## list of names of the author
personProxy, ## that appear in this email
'uod1', 'personNames',
fromPersonNames2.keys())
vsv.newPropertyInstance( ## list of emails of the author
personProxy, ## that appear in this email
'uod2', 'emailAddresses',
fromEmailAddresses2.keys())
emailProxy = vsv.newProxyObject() ## create a proxy for the email itself
vsv.newPropertyInstance( ## unique id ("Message-ID:") of email
emailProxy,
'uod1', 'emailID',
messageIdString)
if len( inReplyToString):
inReplyToProxy = vsv.newProxyObject() ## create a proxy for the email
## to which this email is a
vsv.newPropertyInstance( ## reply, and give it its
inReplyToProxy, ## subject-identifying property.
'uod1', 'emailID',
inReplyToString)
subjectLineProxy = vsv.newProxyObject() ## Create a proxy for the
## email's subject line.
vsv.newPropertyInstance( ## Give it its
subjectLineProxy, ## subject-identifying property.
'uod2', 'subjectLine',
subjectString)
dateProxy = vsv.newProxyObject() ## create a proxy for the email's
## date.
vsv.newPropertyInstance( ## Give it its subject-identifying
dateProxy, ## property.
'uod1', 'date',
dateCode)
## OPs
vsv.newPropertyInstance( ## Let the proxy for the email's
personProxy, ## author reflect that the proxy
'uod1', 'emails', ## for the email is one of the
[ emailProxy.proxyId]) ## ones that were authored by this
## author.
vsv.newPropertyInstance( ## Let the proxy for the email's
personProxy, ## author reflect that the
'uod1', 'emailSubjectLines', ## email's subject line is one
[ subjectLineProxy.proxyId]) ## of the ones that the author
## has written about.
vsv.newPropertyInstance( ## Let the proxy for the email
emailProxy, ## reflect the fact that it was
'uod1', 'sender', ## written by its author.
[ personProxy.proxyId])
vsv.newPropertyInstance( ## Let the proxy for the email
emailProxy, ## reflect the fact that it
'uod1', 'subjectLine', ## has a certain subject line.
[ subjectLineProxy.proxyId])
if len( inReplyToString): ## If the email is in-reply-to
vsv.newPropertyInstance( ## another email, let the proxy
emailProxy, ## for the email reflect that
'uod1', 'inReplyTo', ## fact.
[ inReplyToProxy.proxyId])
vsv.newPropertyInstance( ## Make the email's data the
emailProxy, ## value of the "content"
'uod1', 'content', ## property.
'\n'.join( messages[ messageIdString]))
vsv.newPropertyInstance( ## Let the proxy for the email
emailProxy, ## reflect its relationship to
'uod2', 'date', ## the proxy for the date on
[ dateProxy.proxyId]) ## which the email was sent.
vsv.newPropertyInstance( ## Let the proxy for the subject
subjectLineProxy, ## of the email(s) reflect the
'uod1', 'emails', ## emails that are presumably
[ emailProxy.proxyId]) ## about that subject.
vsv.newPropertyInstance( ## Let the proxy for the calendar
dateProxy, ## day on which the email was sent
'uod1', 'emails', ## reflect its connection to that
[ emailProxy.proxyId]) ## date.
Results
After merging, there is only one proxy for any given
subject, regardless of whether that subject is a person, an
email, an email subject line, or a date. Merging is necessarily
an iterative process, because some mergers can trigger other
mergers.
The resulting subject map can be output in XML. We used
the Versavant engine in order to implement this example. Here
is one of the proxies for a person, in this case, Naito Motomu:
><ProxyObject id="o7811" proxyId="0021224"
><Property
PAppNm="uod1"
PClass="personNames"
IsSIP="Y"
>[u'Motomu Naito']</Property
><Property
PAppNm="uod1"
PClass="emailSubjectLines"
IsSIP="N"
>['0021128', '0020882', '0020690',
'0020706', '0016913', '0021369',
'0021219', '0021392', '0021373',
'0021142']</Property
><Property
PAppNm="uod1"
PClass="emails"
IsSIP="N"
>['0019104', '0019479', '0016933',
'0016912', '0010057', '0019197',
'0011332', '0019733', '0011866',
'0017817']</Property
><Property
PAppNm="uod2"
PClass="emailAddresses"
IsSIP="Y"
>[u'motom@green.ocn.ne.jp']</Property
></ProxyObject
The above proxy has four properties.
The first property is a personNames property, as defined for
the "uod1" universe of discourse. It is a subject-identifying
property (IsSIP="Y") whose value is a list ([]) of names, with
only one item in the list, a Unicode string (u'Motomu
Naito').
In the second property, the value is a list of references
to proxies; 10 proxies are referenced; all of them have email
subject lines as their subjects.
The explanation of the other properties is left as an
exercise for the reader. The whole subject map can be seen at
www.versavant.org/EML2006/
(email-subjectmap.xml).